Traitement et organisation des données de recherche
un guide à l’usage des chercheurs
Rendre les ensembles de données compréhensibles
Les données de recherche existent sous de nombreuses formats (tableaux, images, vidéos, texte).
Dans tous les cas, il est essentiel que l’ensemble de données ait une structure claire et soit compréhensible par d’autres.
Tip
Essayez de vous mettre à la place d’un observateur externe lorsque vous structurez les données.

3. Fournir des métadonnées complètes
Utilisez des métadonnées détaillées (fichiers README et dictionnaires de données/codebook) pour contextualiser et décrire les fichiers de recherche.
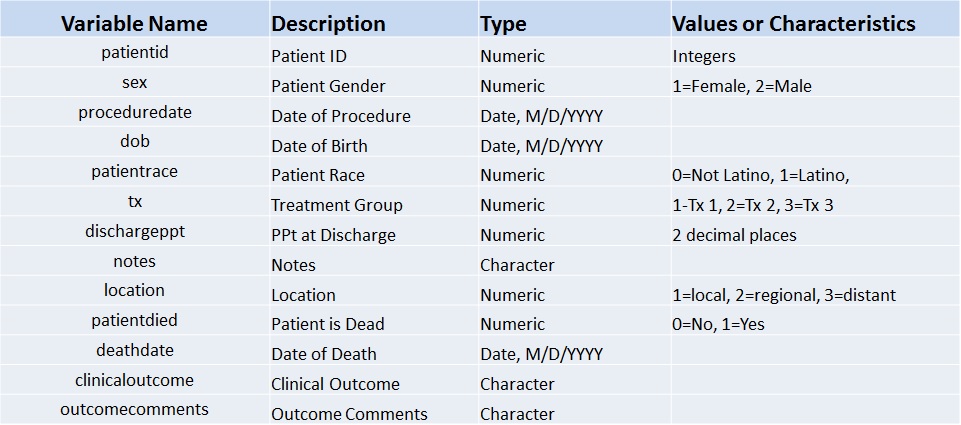
Les tableaux sont au cœur des données de recherche
Bien qu’ils soient le type de fichier le plus courant (.xls) pour l’enregistrement et le stockage des données, les tableaux sont les objets les plus mal organisés et inutilisables en recherche.
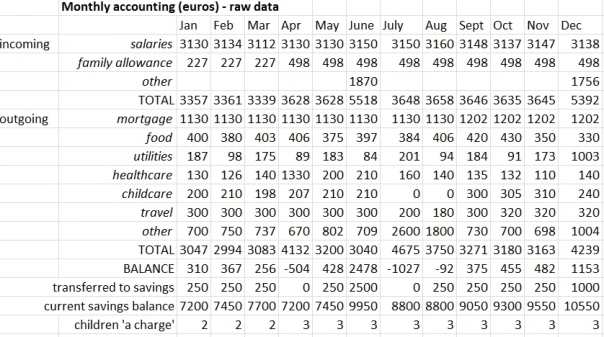
Exemples issus de recherches publiées
_NatureComm.png)
_NatureComm.png)
Exemples de Crystal Lewis (2024)
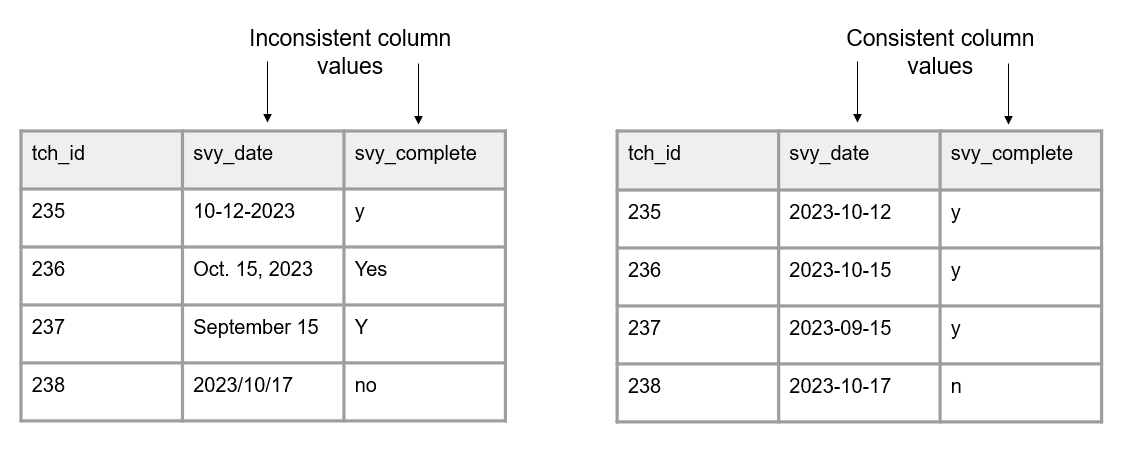
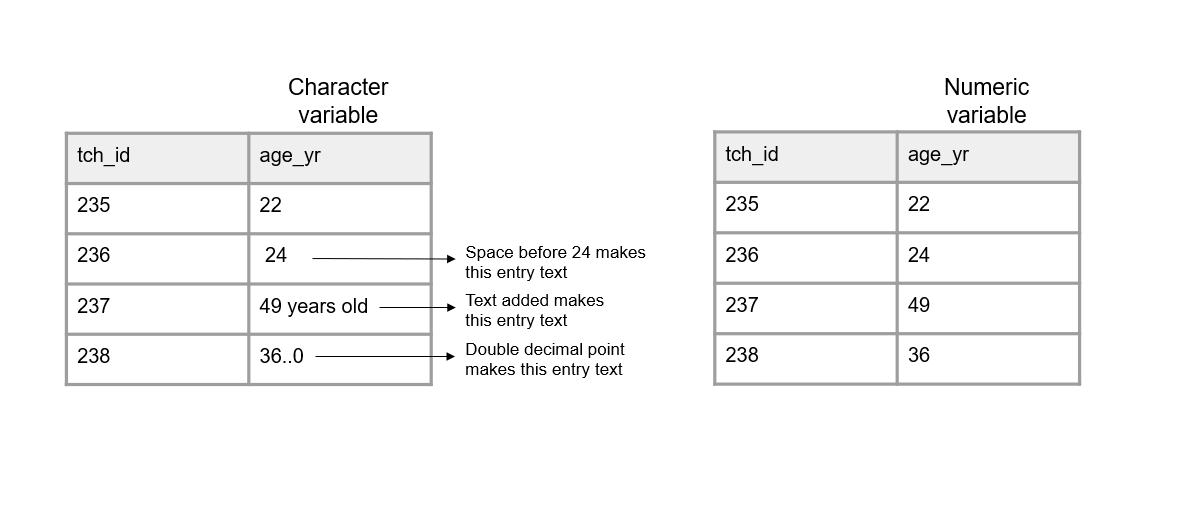
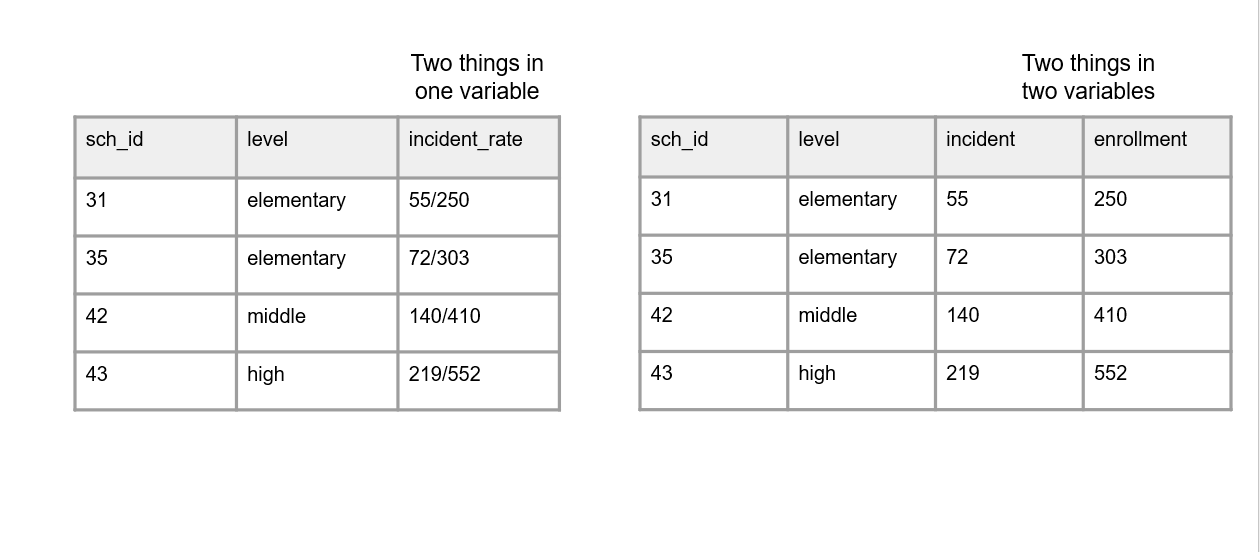
Exemples de Crystal Lewis (2024)
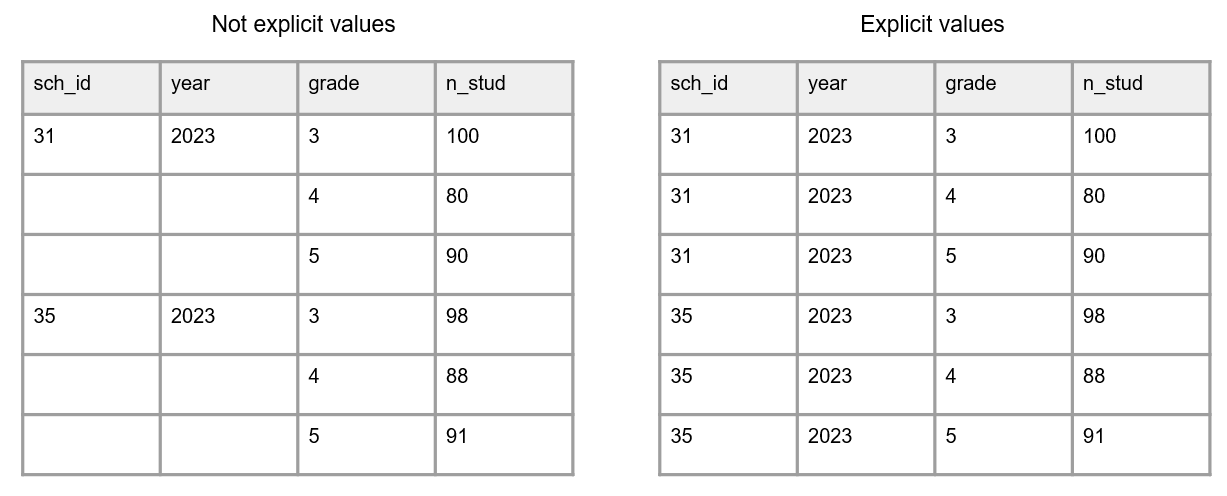
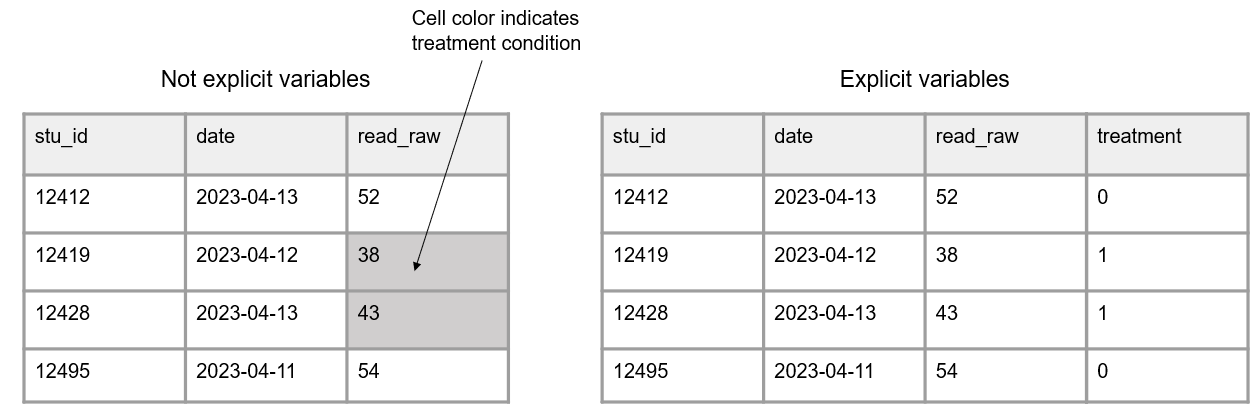
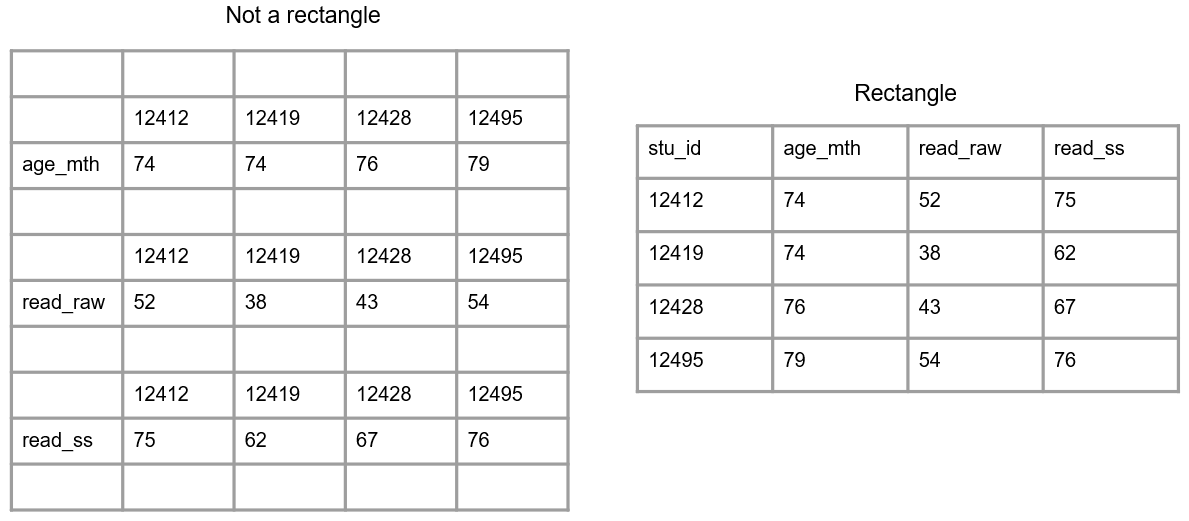
Construire des tableaux de données accessibles
Colonnes
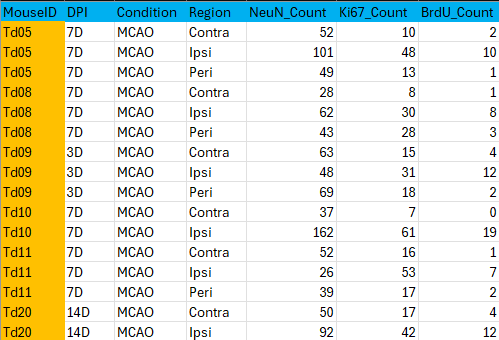
- Variables d’identification : ID animal, point temporel, condition (facteurs ou caractères).
- Variables d’analyse : score, surface, nombre de cellules, etc. (numérique ou catégoriel).
- Variables créées lors du traitement (proportions, ratios, etc.).
Lignes
- Valeurs des variables : entrées pour chaque colonne (variable). Chaque ligne correspond à une observation unique.
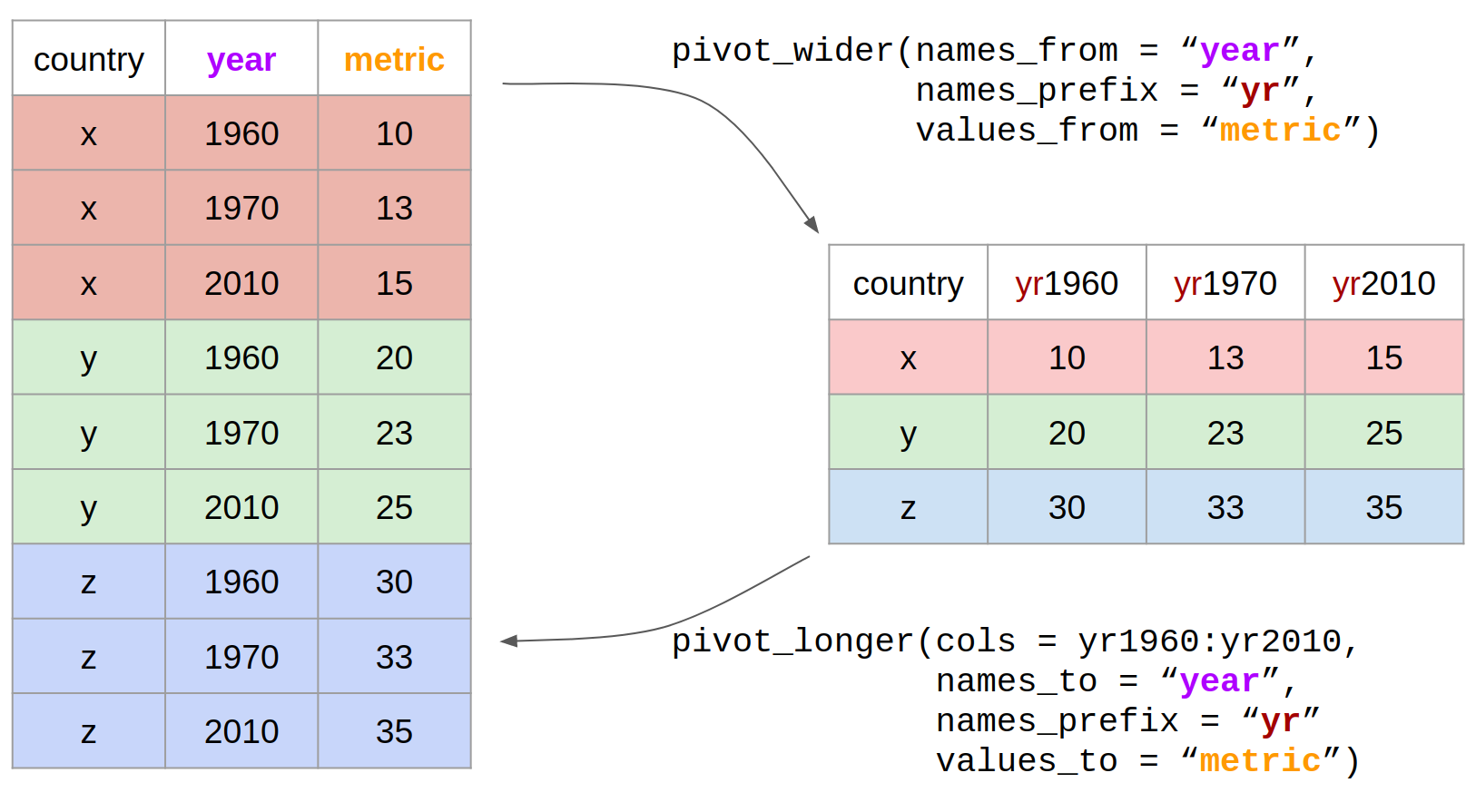
Formats de tableaux larges
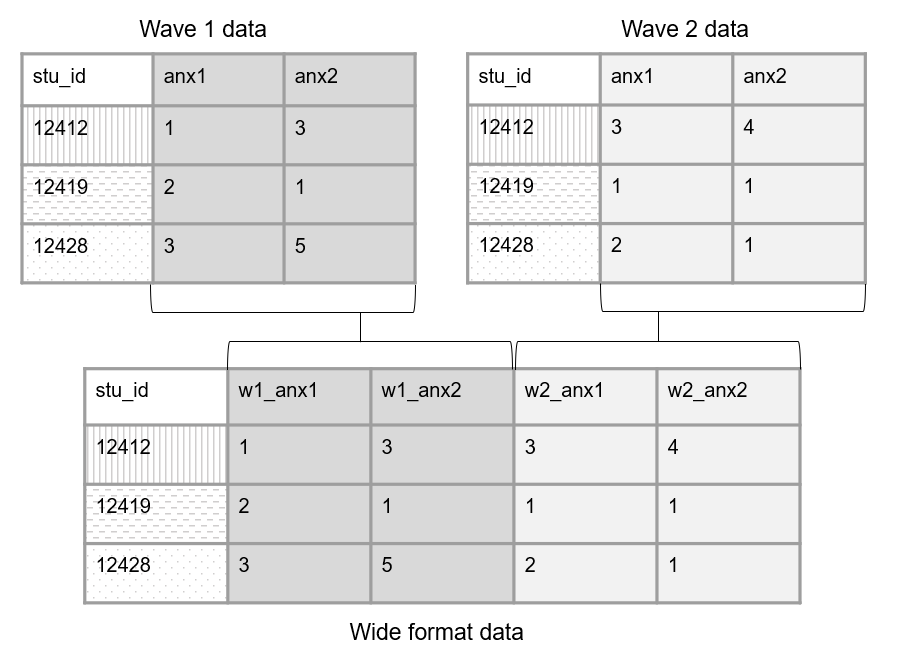
Dans un tableau au format large, chaque sujet occupe une seule ligne et les variables sont disposées en colonnes distinctes : sujet, Id1, Id2, Var1, Var2, Temps 1, Temps 2, Temps 3.
Tip
Ici, les colonnes représentent des réponses ou prédicteurs dans une régression. Exemple :
Cells_7D ~ Cells_2D + Cells_3D.
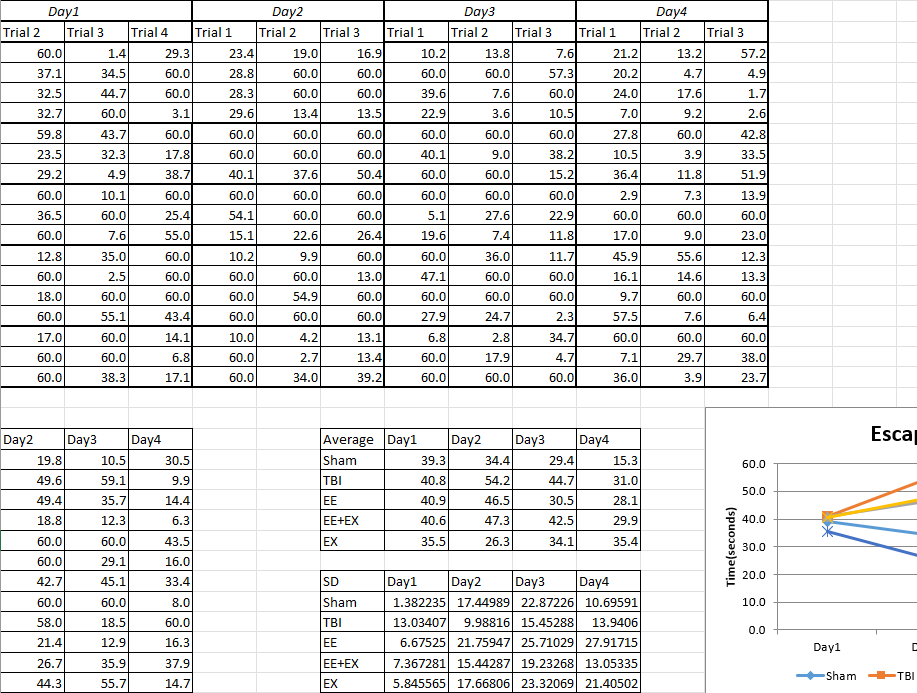
Formats de tableaux longs
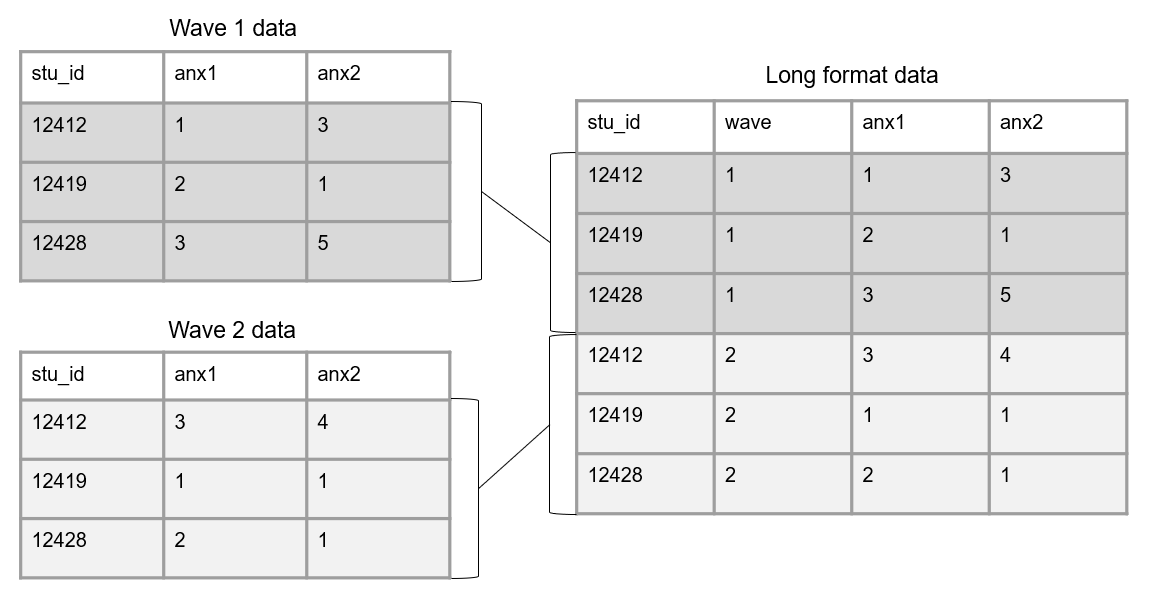
Dans un tableau au format long, chaque sujet occupe plusieurs lignes et possède des observations associées sur différentes lignes :
sujet (répété), Id1, Id2 (répété), Temps (1, 2, 3).
Tip
Utile pour l’analyse des données temporelles, regroupant différentes variables de condition en une seule colonne. Exemple :
Cells ~ PointTemps (1D, 2D, 3D).
Le format long est généralement privilégié pour l’analyse des données.
Le meilleur dans tout ça…
Vous pouvez utiliser R (ou Python) et Quarto pour convertir un tableau du format long au format large, et inversement.
Tip
Consultez les tutoriels R et python.
Fournir des métadonnées (fichiers README)
- Les ensembles de données sont incompréhensibles s’ils ne sont pas accompagnés de dictionnaires de données ou de codebooks (.txt, .md, .csv) décrivant les variables des tableaux de données. Cela peut également prendre la forme d’un fichier README (.txt, .md) qui décrit leur contexte et leur contenu.
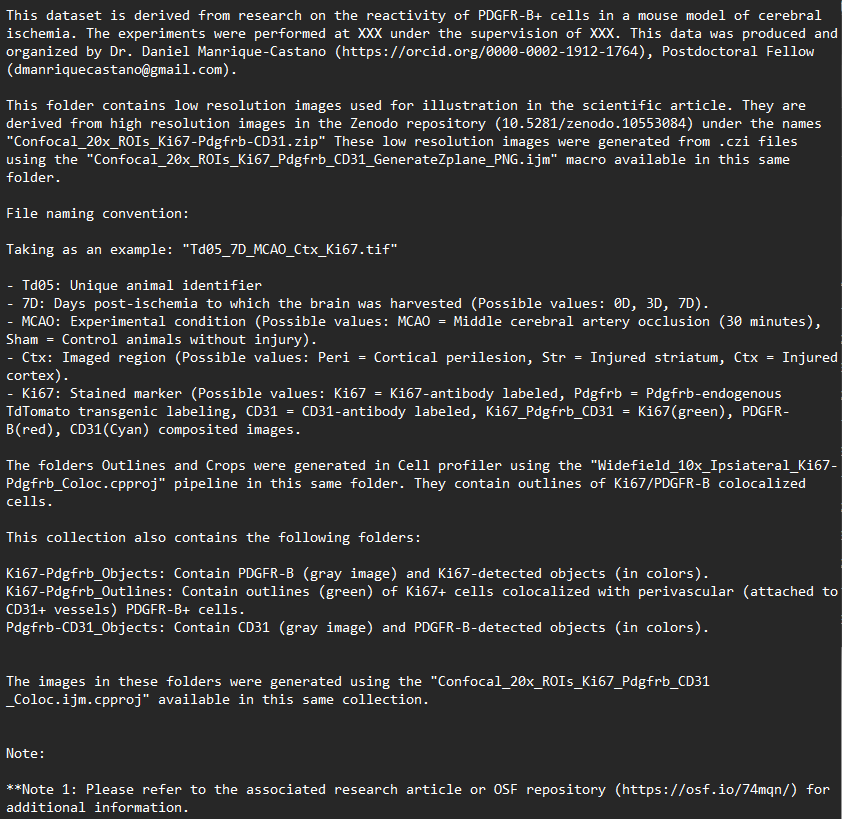
Lors de la gestion des images, veuillez considérer :
- Convertissez les fichiers propriétaires (ex. .czi) en formats ouverts sans compression (.tif).
- Partagez les métadonnées techniques (paramètres d’acquisition) et descriptives (contexte et contenu) avec les images.
- Documentez toutes les procédures appliquées aux images (redimensionnement, soustraction de fond, etc.), par exemple en utilisant un logiciel de codage/script.
- Réalisez les analyses en utilisant un logiciel de codage/script pour garantir la reproductibilité. Évitez l’analyse manuelle.
Tip
Consultez cette ressource pour plus d’informations sur la gestion et le partage des images.
Convertir les images en formats ouverts
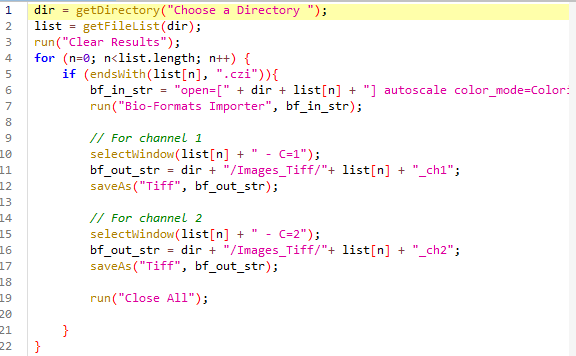
Vous pouvez facilement convertir vos fichiers propriétaires (.czi) en formats ouverts (.tif) en utilisant, par exemple, des scripts FIJI (lien).
Caution
Enregistrer des images .czi en .tif avec FIJI entraîne une perte de métadonnées (archivées dans le fichier .czi).
Suivre les métadonnées
Techniques
Exportez les métadonnées techniques des images propriétaires (ex. .czi) en fichiers .txt ou .csv (cela peut être appliqué à toutes les images d’un lot).
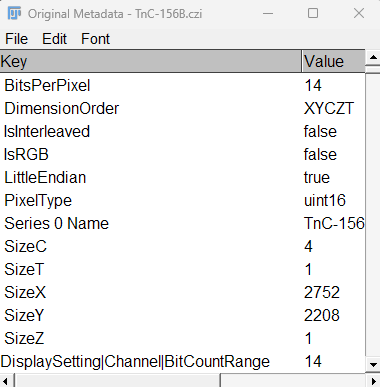
Descriptives
Générez des fichiers README descriptifs pour expliquer la provenance et les conventions de nommage des images.
Un paysage de recherche préoccupant
Nous vivons une pandémie de recherche frauduleuse et irréproducible.
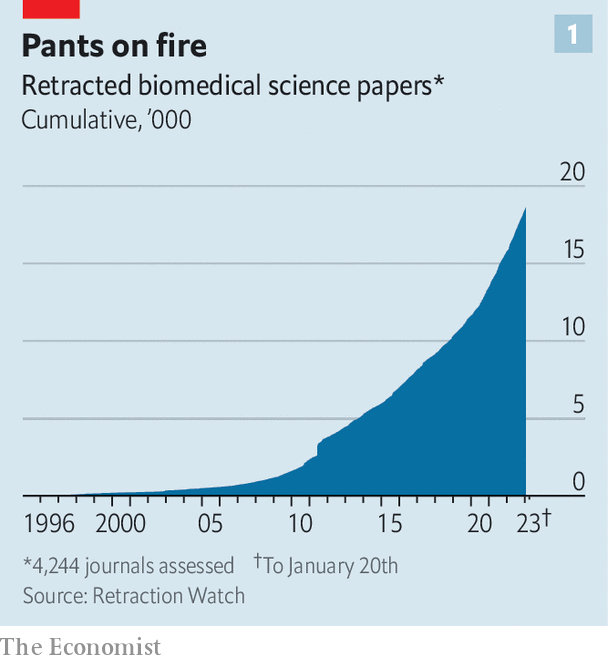
Ce paysage préoccupant exige que, en tant que chercheurs responsables, nous appliquions de bonnes pratiques de recherche pour partager les données et les procédures d’analyse.
Définir la structure d’un ensemble de données
Un ensemble de données structuré est la clé pour le comprendre et le réutiliser.

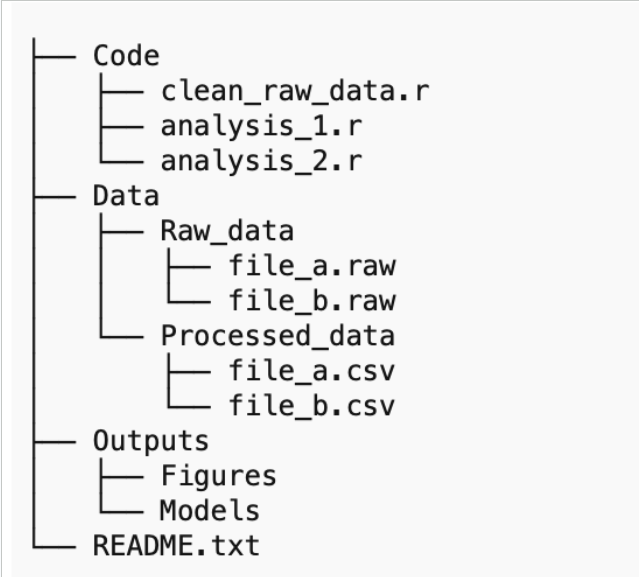
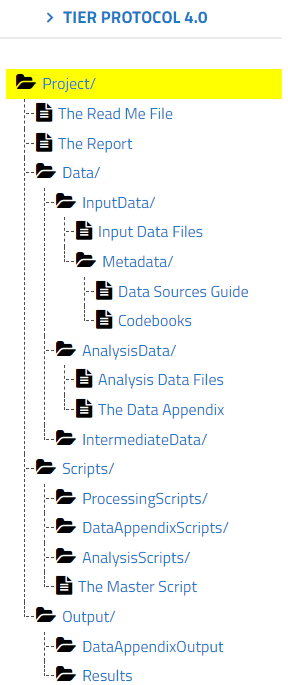
Explorer l’arborescence des dossiers
TIER 4.0 est un modèle de projet conçu pour standardiser les ensembles de données.
Téléchargez la structure du projet et adaptez-la à des cas spécifiques.
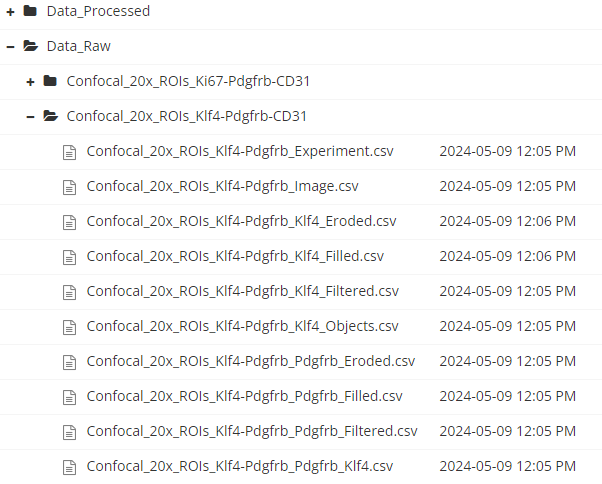
Données brutes
Un dossier Data_Raw/ peut contenir :
- Images originales (.tiff, .czi)
- Fichiers de sortie des appareils de mesure (.txt, .csv)
- Feuilles d’enregistrement originales (.png, .csv, .xlsx)
Données d’analyse (traitées)
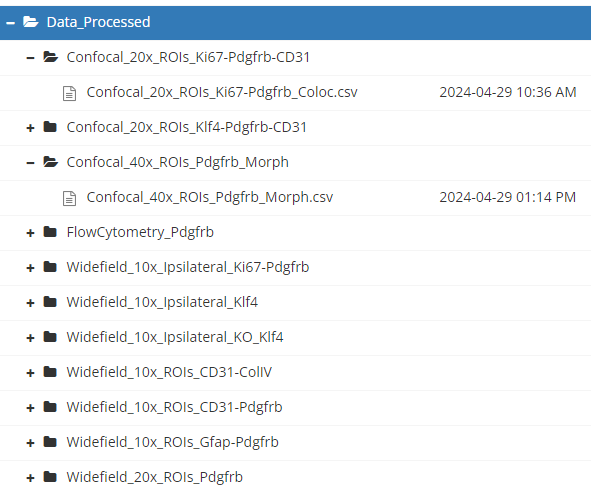
Un dossier Data_Analysis/ contient des fichiers traités utilisés pour générer les résultats de la recherche.
Métadonnées similaires aux données brutes.
Fichiers Data_Appendix présentant des statistiques descriptives de base ou des distributions de données.
Le script est la voie à suivre
Bien que la plupart des chercheurs soient plus à l’aise avec les interfaces graphiques (GUI), le paysage actuel de la recherche exige l’utilisation de scripts et de code pour garantir la reproductibilité des résultats de recherche.

Tip
Le codage doit être considéré comme une compétence essentielle au même titre que d’autres méthodes de recherche.
Outils pour gérer le code et les scripts
R-Studio/Quarto (R + Python)
GitHub (Contrôle de version)
Avec R-Studio (R et Python), vous pouvez
R-Studio/Quarto (R + Python)
Manipuler des tableaux de données et variables avec R et le package Tidyverse.
Traiter des fichiers et données de cytométrie en flux avec R et FlowCore de BioConductor.
Analyser des données de RNA-seq avec R et DESeq2 de BioConductor.
Effectuer des modélisations statistiques avancées avec brms.
Et bien plus encore…
Suivez les versions avec un contrôle de version
Avec GitHub ou GitLab , vous pouvez :
Stocker votre code et vos données en toute sécurité et les partager avec des collaborateurs et le public.
Conserver un historique des modifications et versionner votre code (v 1.0, 1.2, 2.0).
Lier/rendre votre code sur différentes plateformes (ex. Open Science Framework Repository).
Soutenir d’autres chercheurs et contribuer à une culture de science ouverte et reproductible.
Communautés internationales de soutien au codage
Scripts d’analyse
Le dossier Scripts_Analysis contient le code permettant de générer des résultats sous forme de :
- Images
- Figures
- Tableaux
- Modèles statistiques
Tip
Ces scripts importent et traitent les données d’analyse.
Le dossier des résultats
Le dossier Results/ contient les fichiers générés par les scripts d’analyse sous forme de :
- Images
- Figures
- Tableaux
- Modèles statistiques
Fichiers README
Les fichiers README sont des guides pour comprendre les ensembles de données et les tableaux.
Il existe des modèles et des ressources pour guider la rédaction des fichiers README : - Créer un fichier README
- Readme.so
- Readme.ai
Ressources et soutien
Matériel de soutien
- Documentation DFDR
- Ressources de formation de l’Alliance
- RDMkit

Services de soutien
Contactez-nous pour vous assurer que vos données sont bien préparées et peuvent être efficacement partagées avec la communauté.
- Email : rdm-gdr@alliancecan.ca
- Site web du DFDR